I've long been an advocate for the idea that INTEGER! should be an arbitrary precision implementation. It doesn't make sense to me why a high-level language which is targeting future applications would constrain itself to 32-bit, or (in R3-Alpha's case) 64-bit INTEGER! values. I've been trying--for instance--to "futureproof" conversions of INTEGER! to BINARY!, in anticipation of the change.
Now, due to Red's desire to be involved in cryptocurrency, they are adding BIGNUM! as a distinct datatype from INTEGER!. Which is not the way I would do it. INTEGER! already has to detect math overflows in order to give an error when your math is out of range. I would prefer INTEGER! to start out using CPU register-size integers, and instead of erroring on overflows, promote the representation into a bignum...on demand.
The Identity Problem
I suggested that INTEGER! could not hurt for performance for most applications, if it was merely promoted to bignum internal representations on overflow. But there's an issue of identity in bignum operations.
Today this is the behavior for integers:
foo: func [x [integer!]] [add x 1]
smallnum: 0
foo smallnum
print smallnum ; prints 0, unaffected
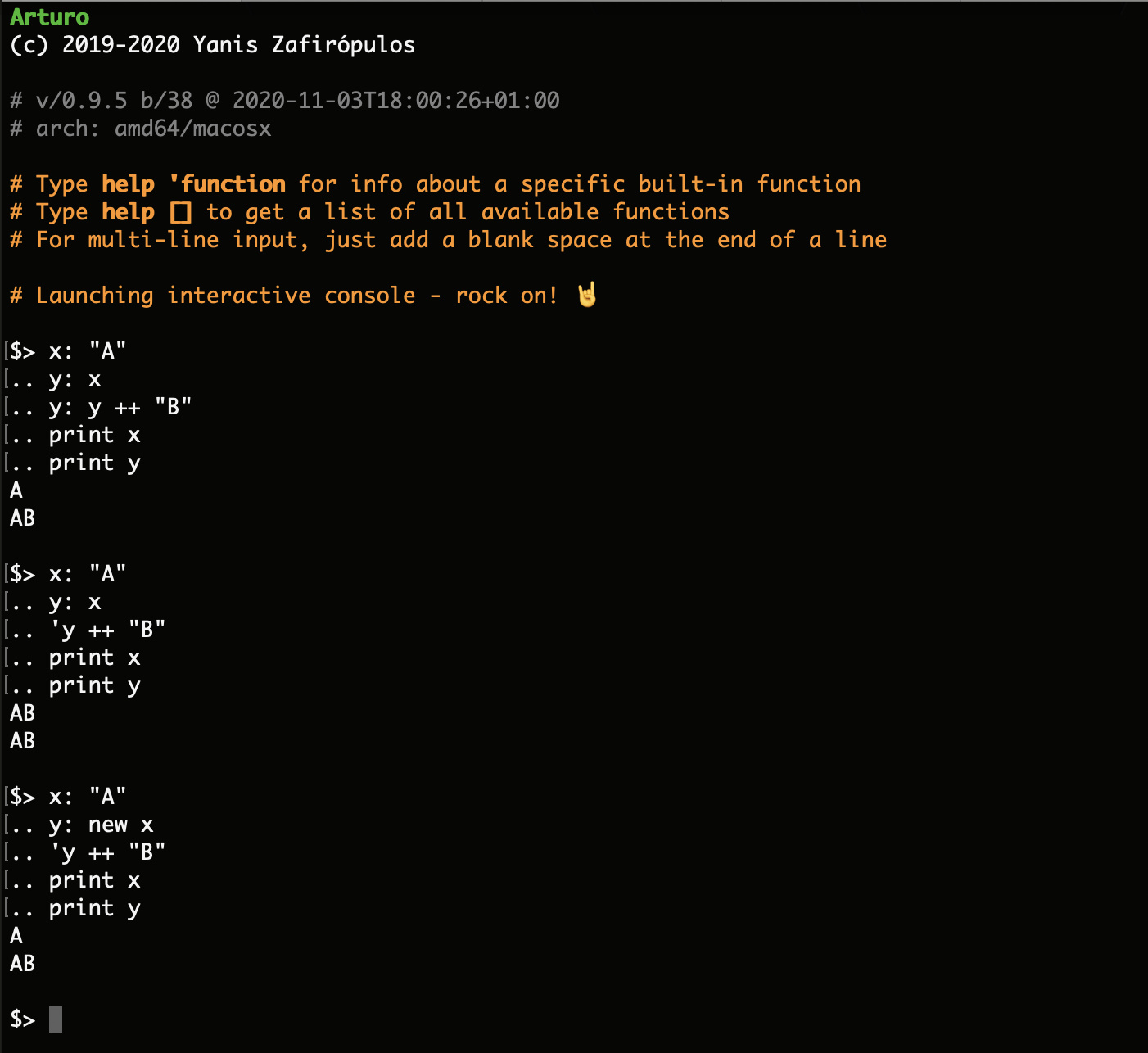
So each integer cell has its own identity (as an ANY-IMMEDIATE!, "immediate value").
ADD or + do not go in and fiddle the bits in a way that is seen by "other instances of that integer", the way that APPEND reaches into the "data node" behind a series and affects all instances.
But with BigNums, making a new identity on each addition can be costly:
bignum: 123456789012345678901234567890
loop 1000000 [
bignum: bignum + 1
]
How many bignum structures should that be "malloc()" ing? Naively done, that would be a million or more allocations, because each addition in Rebol is expected to produce a new-and-disconnected integer.
Getting around this by making ADD mutate BigNum--when it doesn't mutate other things--seems inconsistent. It's not a new problem, there were some issues with ADD of VECTOR!. In Red too, see "Adding a number to a vector changes the vector itself"
Proposal: Mutating ADD, non-mutating +
The thought I had would be that INTEGER!s would not be immediate by their nature, but that literals would be LOCK'd by default.
>> x: 10
>> add x 20
** Error, locked integer
>> x: make integer! 10
>> add x 20
>> print x
30
Then, + would basically be using ADD with a COPY, and locking the result:
+: enfix func [a b] [
lock add copy a b
]
For non-bignums, this could be optimized internally so that if the input was a register-size integer...and the output was a register-size integer...no identity node ever need be created.
So someone can still do an inefficient bignum loop with +, if they really wanted to. But a savvy crypto-person would use ADD so they are modifying the existing bignum in place.
What this does is bolster Rebol's "mutability by default" story about operations like APPEND, bringing it further to ADD. It addresses the issue with VECTOR!, by saying that + will create a new vector while add would mutate the existing one. And it avoids introducing a new BIGNUM! datatype.
Like other changes, this can be skinned with Rebol2/R3-Alpha compatibility to make add 1 2 work in old code that needs it to.
(Note: as a side-benefit, this could remove the need for 64-bit math emulation code on 32-bit platforms. Currently, in an I-believe-to-be-misguided-standardization-effort, Rebol has tried to give those using the interpreter a baseline confidence that INTEGER! has 64-bit representation...even if that's not the native integer type. All that code could go, replaced by bignum code that's needed anyway, if you have any cryptography.)