I wanted to write up some notes about progress on UTF-8 Everywhere, since a couple of weeks ago it was showing the first signs of life for codepoints which would previously cause errors:
And it's not just booting--it's able to do a reasonable amount. It could do this, too.
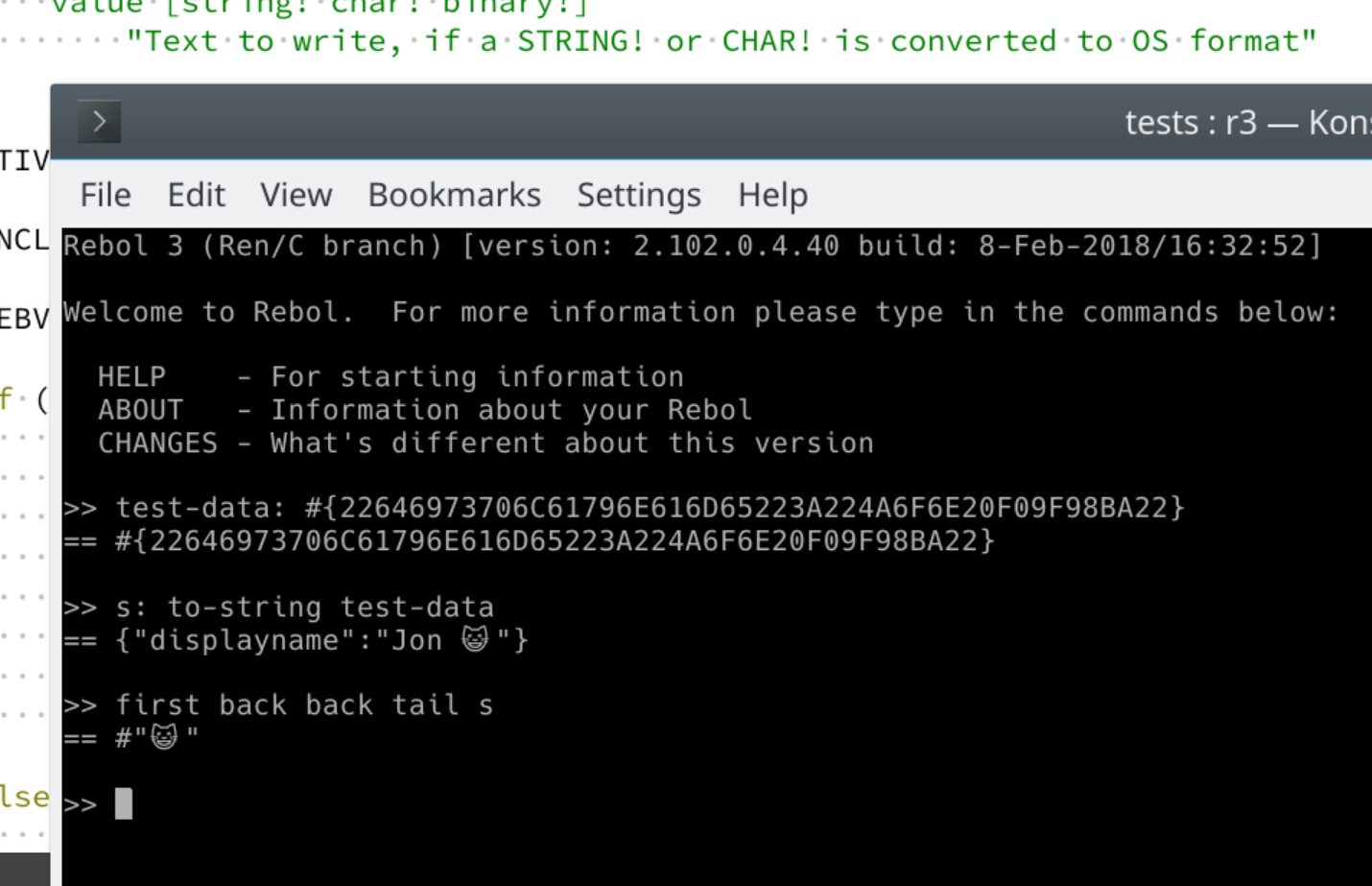
>> bincat: to-binary {C😺T}
== #{43F09F98BA54}
>> parse bincat [{C😺T}]
== true
>> parse bincat [{c😺t}]
== true
>> parse/case bincat [{c😺t}]
== false
>> test: to-binary {The C😺T Test}
== #{5468652043F09F98BA542054657374}
>> parse test [to {c😺t} copy x to space to end]
== true
>> x
== #{43F09F98BA54}
>> to-string x
== "C😺T"
As promising as that looks, I'd say it would be an optimistic to call it "half done". :-/ What needs to be done next is the optimizations avoiding needing to scan strings from the beginning every time you want to translate an index into a character position.
One of the main villains here is the GET_ANY_CHAR() and SET_ANY_CHAR(), which originated in R3-Alpha. They were intended to abstract across BINARY!, Latin1-STRING!, and wide character STRING!. So for instance, PARSE could operate generically on BINARY! and STRING! by using these macros and indexing with them.
But as long as PARSE code tries to use that generality, it's going to be N^2 while iterating. And since PARSE frequently has to iterate its searches repeatedly, that quickly becomes N^3. It's unacceptably slow for day to day use.
So that code must be converted to use iterators, and that iteration has to also be smart about mutation. It's going to take some time, and working on the API and emscripten is higher priority for the moment. But the two tasks kind of tie together, and I've had to rebase parts out of UTF-8 Everywhere a bit at a time...which kind of makes me wish I had more discipline of breaking down commits to being single changes. :-/
In looking around at languages, most are hinged on 2-bytes-per-codepoint, because that's what Windows and Java did. The only one I could find so far that's gone the UTF-8 Everywhere route is Rust. Here's a bit about their "UTF-8 encoded, growable string."
UCS-2 certainly seems an artificial and awkward liability in systems which are trying to handle emojis and such, in systems that only need to support UTF-8. So I was curious if JavaScript implementations were going toward the idea of UTF-8 internally. I found this essay on why when confronted with the need for optimization, they added Latin1 (similar to what R3-Alpha did) instead of just switching to UTF-8:
At this point you may ask: wait, it’s 2014, why use Latin1 and not UTF8? It’s a good question and I did consider UTF8, but it has a number of disadvantages for us, most importantly:
- Gecko is huge and it uses TwoByte strings in most places. Converting all of Gecko to use UTF8 strings is a much bigger project and has its own risks. As described below, we currently inflate Latin1 strings to TwoByte Gecko strings and that was also a potential performance risk, but inflating Latin1 is much faster than inflating UTF8.
- Linear-time indexing: operations like charAt require character indexing to be fast. We discussed solving this by adding a special flag to indicate all characters in the string are ASCII, so that we can still use O(1) indexing in this case. This scheme will only work for ASCII strings, though, so it’s a potential performance risk. An alternative is to have such operations inflate the string from UTF8 to TwoByte, but that’s also not ideal.
- Converting SpiderMonkey’s own string algorithms to work on UTF8 would require a lot more work. This includes changing the irregexp regular expression engine we imported from V8 a few months ago (it already had code to handle Latin1 strings).
So although UTF8 has advantages, with Latin1 I was able to get significant wins in a much shorter time, without the potential performance risks. Also, with all the refactoring I did we’re now in a much better place to add UTF8 in the future, if Gecko ever decides to switch.
So it's interesting to see how tied their hands are, and to consider the benefit of being agile enough to do this change now, before its too late.